Mi a Data Lake? Mi a Data Lakehouse? Különbségek, előnyök, felhasználási példák.

Az adatokkal, analitikával vagy üzleti intelligenciával (BI) foglalkozó szakemberek számára magától értetődőek lehetnek az olyan fogalmak, mint a Data Lake vagy a Data Lakehouse. Ugyanakkor azok számára, akik most ismerkednek ezekkel a technológiákkal, gyakran nem világos, mit is takarnak ezek a kifejezések, milyen problémára kínálnak megoldást, és miben különböznek egymástól.
Mivel a modern adatplatformok vezető technológiája, a Databricks már megjelent Magyarországon is, úgy gondoltuk, hogy hasznos lehet egy közérthető és strukturált ismertetőt készíteni a Data Lake és Data Lakehouse fogalmáról. Az alapoktól kezdve bemutatjuk, hogy hogyan illeszkedik a Data Lake és Data Lakehouse az adatvezérelt rendszerek világába, miben különböznek egymástól és a Data Warehousetól, és miért válhatnak kulcsfontosságúvá egy szervezet stratégiájában.
Tartalomjegyzék
Data Lake - főbb jellemzők és előnyök
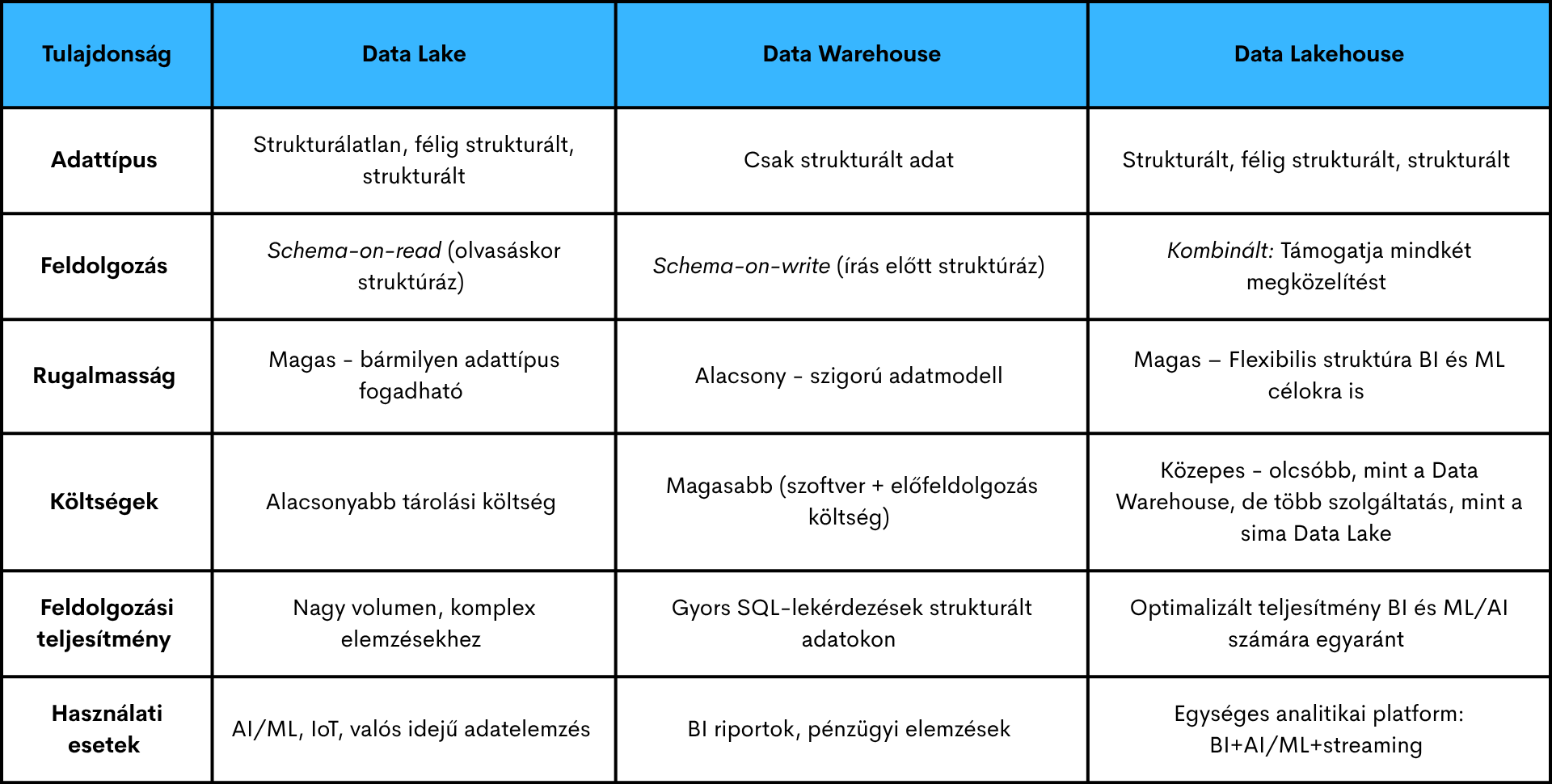
A Data Lake egy központi adattárolási architektúra, amely lehetővé teszi strukturált, félig strukturált és strukturálatlan adatok natív formájában történő, nagy mennyiségű tárolását és későbbi feldolgozását. A Data Lake rugalamas, költséghatékony megoldást kínál big data, gépi tanulás (ML), mesterséges intelligencia (AI) és valós idejű analitika számára anélkül, hogy előre definiált adatmodellt igényelne.
Képzeljük el a Data Lake-t mint egy hatalmas adat-óceánt, ahol az adatfolyamok szabadon beömlenek. Nem szükséges előre tudnunk, mire fogjuk használni ezeket – később “halászhatjuk ki” belőlük a releváns információt.
A Data Lake egy központi adattárolási architektúra, amely lehetővé teszi strukturált, félig strukturált és strukturálatlan adatok natív formájában történő, nagy mennyiségű tárolását és későbbi feldolgozását. A Data Lake rugalamas, költséghatékony megoldást kínál big data, gépi tanulás (ML), mesterséges intelligencia (AI) és valós idejű analitika számára anélkül, hogy előre definiált adatmodellt igényelne.
Képzeljük el a Data Lake-t mint egy hatalmas adat-óceánt, ahol az adatfolyamok szabadon beömlenek. Nem szükséges előre tudnunk, mire fogjuk használni ezeket – később “halászhatjuk ki” belőlük a releváns információt.
Főbb jellemzői:
- Strukturálatlan és strukturált adatok egyaránt kezelhetőek
- Skálázhatóság
- Natív formátumú adattárolás
- Késői adattranszformáció
- Ideális ML és big data projektekhez
A Data Lake népszerűsége az utóbbi években nem csupán a big data és AI technológiák térnyerésének köszönhető, hanem az adatmennyiség folyamatos növekedésének is. Korábban jellemzően fókuszált, előválogatott adatokat tároltak és elemeztek Data Warehouse-okban. A technológiai fejlődés azonban új rendszereket és igényeket hozott magával, így egyre gyakoribbá vált az a szemlélet, hogy minden adatot érdemes megtartani, akár azonnal felhasználják azokat, akár csak később.
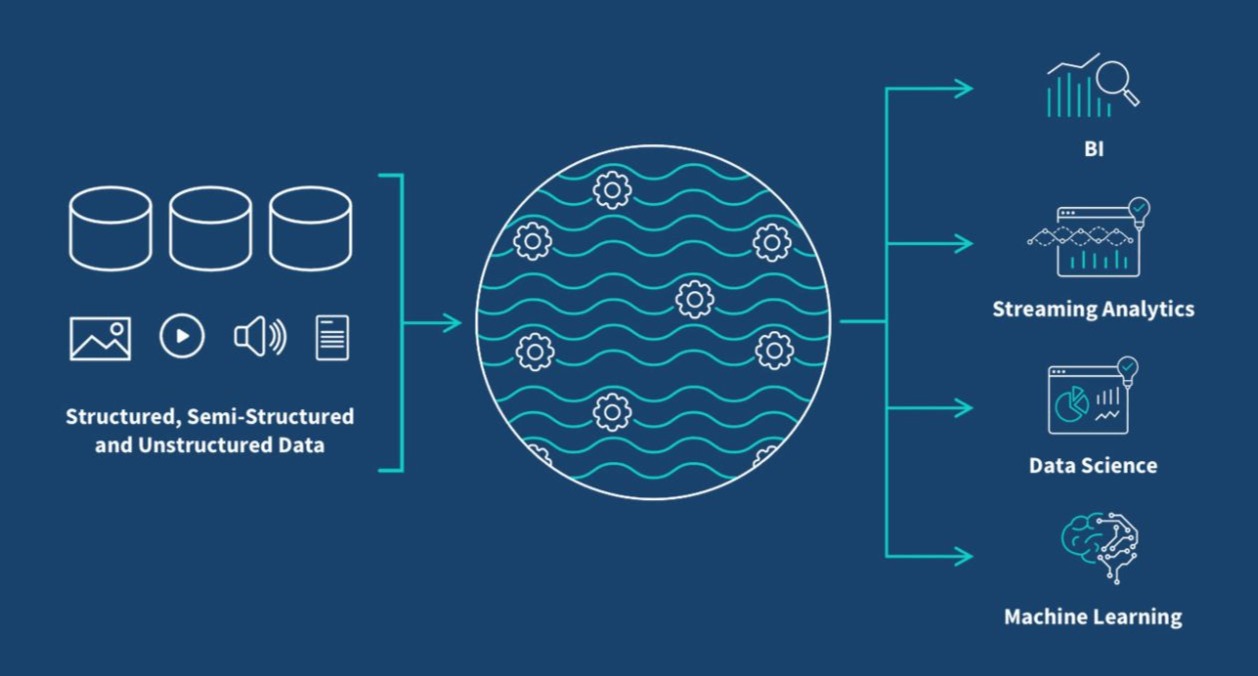
Data Lakehouse - főbb jellemzők és előnyök
A Data Lakehouse egy új, nyílt adatkezelési architektúra, amely a Databricks innovációjaként jött létre. Ötvözi a Data Lake rugalmasságát és skálázhatóságát a data warehouse adatkezelési képességeivel és ACID tranzakcióival. Célja, hogy egyetlen platformon támogassa a BI-t és az AI/ML elemzéseket, kompromisszumok nélkül.
Olyan, mint egy nagy, nyitott raktárt, ahol mindenféle adat dobozban érkezik – rendezetten vagy rendezetlenül -, de belépés után azonnal vonalkódot kap, polcra kerül, és bármikor visszakereshető. Nem kell külön épületet fenntartani a rendezett és a rendezetlen adatnak, mert itt minden típusú adat egy helyen él, mégis ugyanúgy működik egy BI-lekérdezés, mint egy gépi tanulási modell betanítása.
Tehát, egyszerre rugalmas, mint egy Data Lake, és strukturált, mint egy Data Warehouse, mindez a Databricks technológiai alapjaira építve.
Data Lakehouse főbb jellemzői:
- Alacsonyabb költségek
- Jobb adatkezelés
- Adatredundancia csökkentése
- BI és gépi tanulás támogatása
- Változatos munkaterhelések kezelése
- Megbízhatóbb és pontosabb adatok
- Streaming adatok támogatása és batch feldolgozás
- ACID-tranzakciók
- Egyszerűsített architektúra
- Optimalizált teljesítmény
- Skálázhatóság
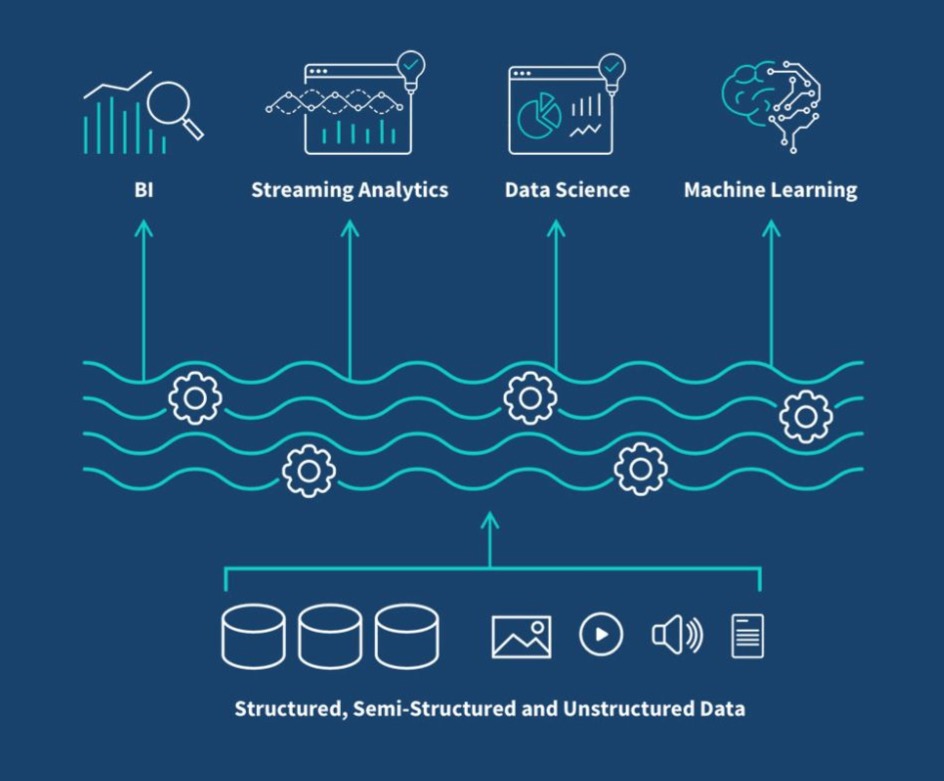
Mire jó a Data Lake vagy Data Lakehouse?
Ahogy a vállalatok egyre több különböző forrásból gyűjtenek adatokat, egyre világosabbá válik, hogy a hagyományos adatbázisok már nem képesek hatékonyan kezelni ezt az adatmennyiséget és sokféleséget. A Data Lake olyan rugalmas és skálázható adattárolási megoldást kínál, amely lehetővé teszi strukturált és strukturálatlan adatok együttes kezelését, feldolgozását és elemzését egy központi helyen, előfeldolgozási kényszer nélkül. Ez nem csak a technológiai rugalmasságot növeli, hanem lehetővé teszi az adatalapú működés gyorsabb bevezetését, a machine learning és mesterséges intelligencia alkalmazását, valamint a valós idejű döntéshozatalt is.
Ugyanakkor sok szervezetnek nem elég pusztán az adatok tárolása, szükség van megbízható adatminőségre, visszakövethetőségre és strukturált lekérdezhetőségre is.
Erre válaszol a Data Lakehouse, amely a Data Lake rugalmasságát és skálázhatóságát ötvözi az adattárházakra jellemző adatkezelési képességekkel.
Így egyetlen platformon lehet kiszolgálni BI- és ML-igényeket is, anélkül, hogy az adatok mozgatásával vagy redundáns tárolásával kellene számolni.
A Databricks szerepe a Data Lake és Data Lakehouse fejlődésében
A Data Lake technológia egyik legjelentősebb innovátora napjainkban a Databricks, amely kulcsszerepet játszott a nyílt, skálázható adatplatformok elterjesztésében, valamint a Data Lakehouse architektúra megalkotásában is. Az Abylonnál mi is aktívan dolgozunk Databricks-alapú megoldások bevezetésén és támogatásán, így napi szinten tapasztaljuk, hogyan alakítja ez a platform a modern adatkezelés jövőjét.
A Data Lake koncepciója eredetileg nyers adatok szabad, előzetes struktúrázás nélküli tárolására épült. Azonban az érettség és igények adatvolumen növekedésével és üzleti igények bővülésével egyre nagyobb szükség lett a megbízható adatkezelésre, verziókövetésre, adatminőségre és BI-kompatibilitásra is. A Databricks ezekre az igényekre válaszul hozta létre a Data Lakehouse modellt, amely ötvözi a Data Lake rugalmasságát és skálázhatóságát a Data Warehouse strukturáltságával és adatkezelési képességeivel egyetlen egységes platformon.
Fő különbségek: Data Lake vs Data Warehouse vs Data Lakehouse
A modern adatvezérelt vállalatok számára kulcsfontosságú kérdés, hogy Data Lake, Data Warehouse vagy a kettő előnyeit ötvöző Data Lakehouse architektúrát válasszanak. Bár mindhárom megoldás célja egyaránt az adatok tárolása és elérhetővé tétele, alapvetően eltérnek abban, hogy milyen típusú adatokat, hogyan és milyen célokra képesek kezelni.
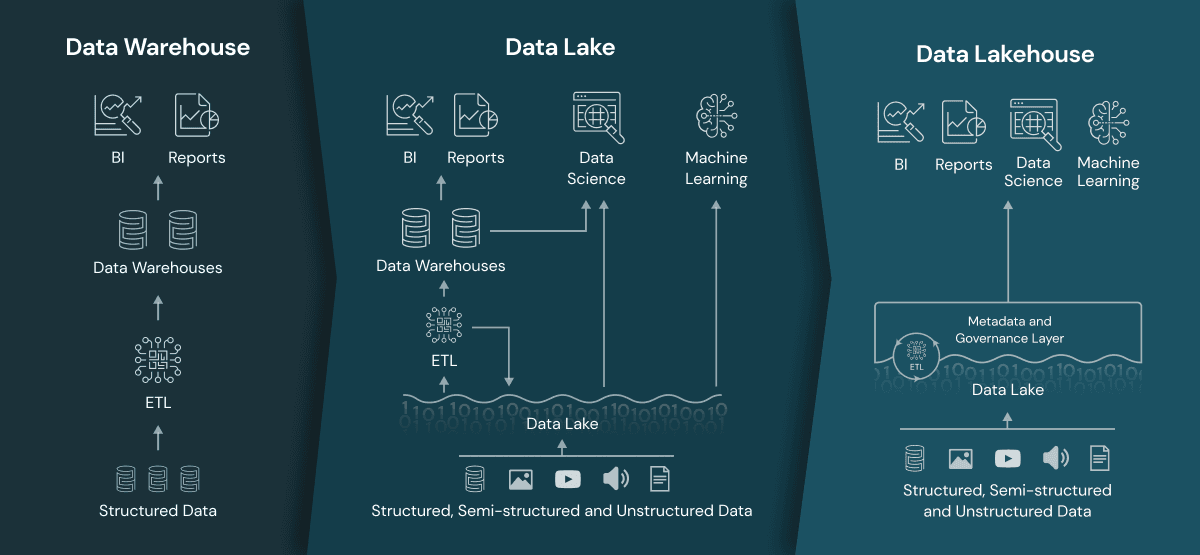
Fentebb már kifejtettük, hogy mi is a Data Lake és Data Lakehouse, nézzük meg, hogy hozzájuk képest miben különbözik a Data Warehouse. A Data Warehouse egy strukturált adattár, amely jellemzően előfeldolgozott, jól szervezett, relációs adatokat tárol, elsősorban üzleti riporting és BI célokra.
Egy szupermarket például naponta több ezer tranzakciót bonyolít le, és ezek adatait rendszerezve tárolja egy Data Warehouse-ban. Így a vezetők pontosan meg tudják mondani, melyik termék fogy a leggyorsabban egy adott boltban, mikor érdemes készletet feltölteni, vagy milyen termékekre lenne érdemes akciót indítani.
A Data Lake előnyei
Költséghatékonyság
A Data Lake infrastruktúrák, különösen a felhőalapú tárolók, jóval kedvezőbb költségstruktúrát kínálnak, mint a hagyományos adattárházak. Az adatokat natív formában, olcsó objektumtárolókban lehet tárolni, és csak akkor történik feldolgozás, amikor az adatokra valóban szükség van.
Skálázhatóság
A Data Lake megoldások, különösen a felhőalapú platformokon (pl. Amazon S3, Azure Data Lake Storage), szinte korlátlan tárhelykapacitást kínálnak. Ez lehetővé teszi nagy adatamennyiségek hatékony kezelését, ami elengedhetetlen a Big Data környezetben.
Rugalmasság
A Data Lake támogatja a strukturált (pl. SQL adatbázis), félig strukturált (pl. JSON, XML) és strukturálatlan (pl. képek, videók, logfájlok) adatok tárolását egyaránt. Ez különösen hasznos olyan szervezeteknél, ahol sokféle forrásból származó adatokat kell egységes módon kezelni.
Gyors adatbevitel
Mivel nincs szükség az adatok előfeldolgozására (schema-on-write), a Data Lake lehetővé teszi az adatok azonnali rögzítését és tárolását natív formájukban. Ez felgyorsítja az adatbeviteli folyamatokat és csökkenti a késleltetést a begyűjtés és az elemzés között.
ML/AI támogatás
A machine learning és mesterséges intelligencia algoritmusok sokféle és nagy volumenű adatokon működnek a leghatékonyabban. A Data Lake ideális környezetet biztosít ezekhez a projektekhez, hiszen nem korlátozza adatformátum vagy struktúra.
A Data Lake típusai
Cloud-alapú Data Lake:
A cloud Data Lake olyan adattó, amely egy felhőszolgáltató infrastruktúráján működik, például Amazon S3, Google Cloud Storage vagy Microsoft Azure Data Lake Storage platformon. Ezek teljes mértékben menedzselt, rugalmas megoldások, amelyek ideálisak nagy mennyiségű adat tárolására és feldolgozására minimális IT infrastruktúra-kezelés mellett.
Fő előnyök:
- Korlátlan skálázhatóság
- Automatikus biztonsági funkciók és hozzáférés-kezelés
- Magas rugalmasság, gyors adattárolás és elérés
- Könnyű integráció machine learning, big data és valós idejű analitikai eszközökkel
On-premises Data Lake:
Az on-premises adattó saját adatközpontban futó megoldás, ahol a szervezet teljes mértékben kontrollálja az infrastruktúrát és az adatokat. Ez különösen előnyös azokban az iparágakban, ahol magas a szabályozottság és az adatvédelem kritikus.
Fő előnyök:
- Teljes adatkontroll és hozzáférés-kezelés
- Kompatibilis a szigorú iparági szabványokkal
- Helyi hálózatokra optimalizálható, alacsony késleltetésű működés
Hibrid Data Lake:
A hibrid Data Lake ötvözi a felhőalapú és on-premise adattárolási lehetőségeket. Ez lehetővé teszi, hogy a vállalat kihasználja a felhő rugalmasságát és költséghatékonyságát a kevésbé érzékeny adatoknál, miközben a kritikus, bizalmas adatokat továbbra is helyben tárolja.
Fő előnyök:
- Rugalmas adattárolás a költségoptimalizálás érdekében
- Adatszuverenitás biztosítása érzékeny adatok esetén
- Adatintegrációs lehetőségek felhő és helyi rendszerek között
Open source Data Lake:
Az open source Data Lake olyan rendszerekre épül, mint az Apache Hadoop, Apache Spark vagy Apache Flink. Ezek általában testreszabhatóbbak, viszont nagyobb szakértelmet és belső erőforrást igényelnek a bevezetéshez és üzemeltetéshez. Elérhetők on-premise, de gyakran futnak konténerizált formában felhőalapú környezetben is.
Fő előnyök:
- Költségmegtakarítás a licencek elkerülésével
- Magas testreszabhatóság és bővíthetőség
- Aktív fejlesztői közösség és támogatás
A Data Lakehouse előnyei
Egységes platform BI és AI/ML célokra
Data Lakehouse lehetővé teszi, hogy üzleti riportok és gépi tanulási modellek egyaránt ugyanazon az adattárolási rétegen működjenek – külön adatmozgatás, duplikáció vagy infrastruktúra nélkül.
Strukturált és strukturálatlan adatok kezelése
Akárcsak a Data Lake, a Data Lakehouse is képes natív formában fogadni és tárolni különböző típusú adatokat, ugyanakkor ezek a rendszerek már támogatják a sémaellenőrzést és szabályozott adathozzáférést is.
ACID-tranzakciók és adatkonzisztencia
A Data Lakehouse támogatja az adattárházakból ismert megbízható adatkezelési képességeket. Így az adatfrissítések és törlések is biztonságosan kezelhetők, még nagyméretű rendszerekben is.
Egyszerűsített architektúra
Mivel a Data Lakehouse egyesíti a Data Lake és Data Warehouse funkciókat, nincs szükség két külön rendszer fenntartására, szinkronizálásra vagy adatátmozgatásra. Ez csökkenti a komplexitást és a költségeket.
Skálázhatóság és költséghatékonyság
A Data Lakehouse architektúrák jellemzően felhőalapú, objektumtárolón alapuló megoldásokra épülnek, így egyszerre biztosítják a nagy adattömegek tárolását és a skálázható számítási teljesítményt.
Nyílt formátumok és eszközfüggetlenség
A modern Data Lakehouse rendszerek (pl. Databricks Delta Lake) nyílt formátumokat használnak, amelyek többféle elemző és feldolgozó eszközzel is kompatibilisek.
Date Lake vagy Data Lakehouse fejlesztés
Kíváncsi rá, milyen előnyökkel járhat vállalata számára a Data Lake vagy Data Lakehouse technológia? Kérjen konzultációt, örömmel segítünk feltérképezni a lehetőségeket, és megtervezni a következő lépéseket.
Az Abylon, hivatalos Databricks partnerként, tapasztalt tanácsadócsapatával támogatja ügyfeleit a modern adatplatformok világában – legyen szó stratégiai tervezésről vagy technológiai megvalósításról.
Attól függetlenül, hogy csak most ismerkedik a Databricks technológiával vagy már létező megoldást fejlesztene vagy bővítene tovább, érdemes megnézni az Abylon által kínált Databricks QuickStart csomagokat.
Vegye fel velünk a kapcsolatot, és nézzük meg együtt, hogyan építhet hatékony, skálázható adatinfrastruktúrát Databricks-alapokon, Data Lake vagy Data Lakehouse architektúrával.