For whom this blogpost is meant for
IT professionals who work with data, optionally familiar with BI or Datawarehouse technologies, and may need to create a solution in which they need to create posting files or an interface for accounting /ERP systems from historical data. This article can help them to identify the required actions and things to consider.
On the other hand, it is also intended for financial professionals or Business Analysts who are involved in a project or projects where the goal is to develop an interface between normal transaction systems and accounting/ERP systems.
Intro
What is posting in accounting?
If you know what an SCD, or even a SCD2 is, feel free to jump on to the task description. If you don’t know what they mean, the following few lines can help you understand.
As part of the month-end closing process, it is always necessary to make numerous manual postings in the financial accounting. Posting in accounting is when the balances in sub-ledgers and the general journal are shifted into the general ledger. Posting only transfers the total balance in a sub-ledger into the general ledger, not the individual transactions in the sub-ledger. In other words, after you enter, review, and approve transactions, you must post them to update your systems with current transaction records and maintain system integrity.
What is an SCD?
SCD stands for Slowly Changing Dimension, and is essentially a data structure that allows us to keep track of changes in our data.
What does “data change” mean?
In the world of IT, we typically store data in relational and non-relational databases. In this article, we start with relational databases, which are typically stored in SQL databases. Data entry is usually done through some kind of application where users input data using a desktop or sometimes some mobile device. No matter how, but the data eventually ends up in a data table. Consider a typical transaction: a sale event occurs and the following data (also called a record in a database language), that is, records are created

A data changes occur when a change, modification or deletion occurs in the already created and stored data (in this case the data above). SCD types are intended to symbolize the handling of the above changes.
More info on SCD:
https://www.datawarehouse4u.info/SCD-Slowly-Changing-Dimensions.html
https://www.allthingssql.com/slowly-changing-dimension-types/
For example, SCD0 means that no changes are allowed to the previous data – (in practice, this is how transactions are stored in Block chain technologies, where you cannot delete or modify previous transaction data).
SCD1 is when we pass all changes to the current data file and do not store anywhere what data was stored before. Technically, SCD1 can already be considered a historization.
In this post, we show one of the benefits of SCD2 and how this type of historization can be used to create appropriate monthly posting files or a proper interface for accounting. You can read more about SCD2 and the different SCD formats following the links above
The task: Create a posting file with retroactive – aka. closed periods adjusting
Let’s suppose our company builds a calculation engine (hereinafter: the engine) in a database that receives transaction data from an application and then recalculates the transaction values from the received transaction data each time it runs.
( It doesn’t matter if this is a separate database, a database schema, or part of a transaction system to be developed, this solution is feasible in any case. I will now describe a solution where the transaction data is transferred using ETL processes to another database, and some of the calculations take place there, not in the application itself )
Several transformations can occur in the database that do not happen on the application side, e.g. Exchange rate assignment, assignment of partner data, product info, even purchase data, purchase prices, etc. On every run the engine receives the data from the application and from all other source systems and completely re-calculates the output data.
In our case, it is also the job of the engine to produce a posting file (or an interface) for the accounting program at an unspecified time at the beginning of each month. This part of the process is done manually, there is no automated running and data extraction
The Challenge
The engine completely recalculates everything on each run – clears the entire table contents at the database level (TRUNCATE) and loads the calculated data completely (INSERT).
Posting, on the other hand, occurs once a month at an unspecified time, during which only a portion of the calculated data (typically data for the previous month) is loaded into the accounting software (or ERP), based on a predefined field containing the transaction date.
The business analysis revealed that some transaction data may change even months after the first recording (UPDATE).
We did not receive any information regarding the possibility of data deletion during the development, however, it cannot be completely ruled out from the engine’s point of view
So to sum up the problem: how can we ensure the consistency of the calculated current data and the accounting data at the analytical level in the long run?
Let’s see our Example:
The transaction system will be launched in January 2022, and will be showing the following transactions when they are imported on the 2nd of February:

On the 3rd or March 2022 (the time of the next monthly posting/import) the whole transaction data set will look like this:
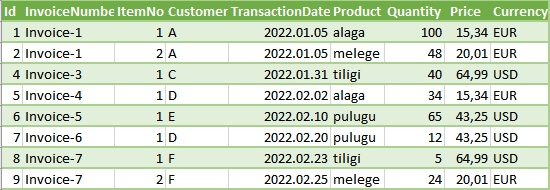
During the import on 3rd of March 2022, according to the protocol, only the data with the February TransactionDate (aka. PostingDate) will be loaded into the accounting system, however, we can see in the example that the data line (record) with the ID 3 has been deleted and for the record with Id 2, the Quantity was changed from 50 to 48.
The Alternatives
During the posting (in the posting file), we can follow the general cancellation rules, ie we make a change by adding the value of the previously recorded transaction with a negative sign (we can also post a canceled transaction in this way), and then re-enter the value and data of the correct transaction.
If the accounting software or ERP allows it, it is advisable to record the fact of the cancellation, and to record the ID linking the posted item to the original transaction together with the accounting item. (In our case there are two options: it is logical to use an ID field for this, however, if for some reason this field is not available, the InvoiceNumber and ItemNo lines can clearly identify a record, so we could use those as well).
A possible solution would be if the accounting system would always receive the full calculation, but this would cause a lot of data redundancy that would only make data reconciliation between the accounting and the engine even more difficult.
So keep in mind to make it as easy as possible to reconcile the differences.
The Solution: Historization and SCD2 helps!
First of all, we introduce historization into the engine in at least SCD2 format. During historization, it is sufficient to historize the final table containing each calculation step.
Historization – illustrated with data below – is done by introducing 2 Flag fields as well as two date fields, a DAT_FROM and a DAT_TO field, which show the validity period of the given transaction record.
The two flags are FLG_IS_CURRENT and FLG_IS_DELETED. Flags are managed as Bits, so they can only take a value of 0 or 1, 0 is false and 1 is true. (This form of SCD2 is just an option, no obligation for the data types, nor for the column names, etc. Try to grasp only it’s logic, if you are not familiar with it.
For the historization you will need to select the key field or key fields, using which the items can be clearly identified. These key fields determine whether an item was previously included in the data or not, and the modification steps are also performed based on these key fields.
When entering the system the current data will get the current date / time in the DAT_FROM field, the value of FLG_IS_CURRENT will be 1, the value of FLG_IS_DELETED = 0, and the value of the DAT_TO field will either be empty, ie NULL or e.g. 2999-12-31.
(I suggest a preferably high default value for the DAT_TO field, because NULL’s are mostly incomparable in rdbms systems.)
If an item is deleted, FLG_IS_CURRENT will be 0, FLG_IS_DELETED will be 1, and the DAT_TO value field will be updated to the time of the change.
If modified, the value of the FLG_IS_CURRENT field for the modified record changes to 0, and the value of DAT_TO changes to the time the change is registered (when the modified field is historized), and the field with new values is entered as the current new value in the historized table.
It is a good idea to store the current and historical tables in separate tables.
In the above case the HISTORY table would look like this on the 3rd of March 2022:
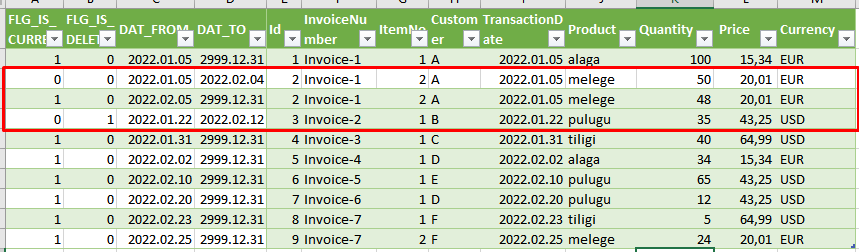
We can see that both items from January, which were modified, were modified in February, after the date of the last dispatch/import (February 2)
Preparing for posting/import
In order to be able to correct the posting with previously deleted or modified items, whether we export them manually or automatically for posting, we must record the date of the export. Let’s call this the DateOfExport parameter.
It is advisable to organize the actual solution by supplementing the record files containing the current transactions together with the plus sets needed for the corrections (and providing the sets with the appropriate signs), which can be handled to perform all the modification and transformation steps in the engine together which helps to produce the posting file.
The following figure will help you understand which sets to add to the current one for this purpose:

Explanation:
- The blue and red areas are the ones that output the entire dataset that needs to be transformed.
- The blue areas are the ones that are counted with their original sign, the red ones are calculated with the opposite sign.
- It can be seen that only part of the entire ACTUAL file, is exported. The export is based on the original PostingDate field of the transaction data, that is, when the transaction was created.
- The @LastDateOfExport is the date when previous month’s data was exported.
- In addition to the current monthly data of the current record file, we need to add three sets of data:
- Deleted records: Records for which the following conditions are true in the historized table (each condition must be met, i.e. there is an “and” relationship between the conditions):
- FLG_IS_CURRENT = 0
- FLG_IS_DELETED = 1
- DAT_TO › @LastDateOfExport – this guarantees that items that have been deleted AFTER a previous export will now be entered with a negative sign in the record set before the transformation.
- Historical data for modified records with a negative (opposite) sign: these are the records for which the following conditions are true in the historized table (each condition must be met, so there is an “and” relationship between the conditions):
- FLG_IS_CURRENT = 0
- FLG_IS_DELETED = 0
- the value of @LastDateOfExport is between the DAT_FROM and DAT_TO records
- Current data of modified records: all records from the entire current set whose identifiers are included in the records defined in set 2. These are not duplications because they only contain records that were already current in a previous post, but their DAT_TO is greater than their @LastDateOfExport. The sign of the values of the present set is not changed.
- Deleted records: Records for which the following conditions are true in the historized table (each condition must be met, i.e. there is an “and” relationship between the conditions):
- One important modification: for all non-current records, the PostingDate value, ie the date value based on which it is selected for the given monthly post export, is changed to DAT_TO, thus guaranteeing that the added sets are included in the actual post file
The base record set generated this way:
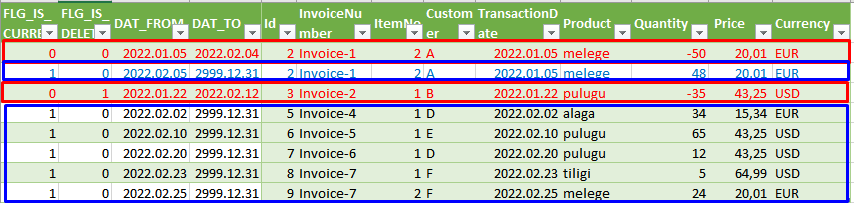
We handle the above sets as a single input and we perform the transformations that are required for the sets to be accepted by the accounting software or ERP.
This blog entry does not cover this topic because these transformation are all target system specific and do not affect the data set and historization operations described above.
Benefits of this approach vs. other approaches
- We don’t do a complete data file load into the accounting software or ERP system every time we do a posting. We do not burden the accounting systems with unnecessary records, simplifying the reconciliation.
- We ensure continuous matching at the analytical level between the accounting software / ERP system and the reports showing the current data (eg towards partners)
- We facilitates analytical reconciliations — especially when IDs are included in the posting file so that cancellation events (items recorded with the opposite sign) can be marked separately. This also facilitates coordination with partners and monthly and annual closing tasks.
- We can also use this in case of automated connection. The only task is to store the DateOfExport value (recordeed manually in the present case study) in the “engine” after the successful posting.
- We cover almost every possible business need creating a robust solution that is prepared for future requests. For example, even if initially there has been no demand to manage cancellations, if such requirement may arise later the engine will be prepared for this
Just one last thing:
Our Rapid solutions (Rapid Planning and Rapid Analytics) provide the ability to use all of the slowly change data management methodologies at the data warehouse level, so our company and our clients can easily create data market solutions supplemented with historization, based on which “time-machine” tabular models can be created. For example our datawarehouse automation solution (Rapid Analytics) is ideal for default historicization solutions
Thank you for your time! I hope you liked my post and found it useful. If you have any comments, additions or questions feel free to contact me at kreiszzs@abylon.io

Author of the post:
Zsolt Kreisz - Financial Controller in the past, now BI Consultant at Abylon Consulting. Linkedin Profile